

Comprendre les flux de données et les protocoles de Solana (Shreds, gRPC, WS, UDP)
Comprendre les flux de données et les protocoles de Solana (Shreds, gRPC, WS, UDP)

Lorsque vous pensez à accélérer votre application Solana ou votre stratégie de trading, les premières choses à clarifier ne sont pas le code ou les spécifications du serveur.
Le point de départ est deux questions fondamentales.
D'abord, vous êtes loin des validateurs de Solana dont vous vous souciez?
Dans quelle région votre application vit-elle réellement, et combien de millisecondes faut-il pour atteindre un validateur à partir de là? Cette distance est le fondement de tout. Si la distance est erronée, aucune quantité de logiciel ou d'optimisation matérielle ne débloquera les performances qui devraient être possibles.
Deuxièmement, où est le validateur de chef à un moment donné?
Lorsque Francfort est le leader, les nœuds près de Francfort sont structurellement favorisés. Quand Tokyo est le leader, les nœuds proches de Tokyo sont favorisés. Les leaders de Solana tournent autour de la slot du globe par slot. Tant que cette propriété existe, une configuration d'une seule région aura toujours des fenêtres de temps où elle est physiquement désavantagée.
Dans la pratique, cela signifie qu'une stratégie réaliste doit être multi-régions.
En plaçant l'infrastructure dans plusieurs endroits tels que Francfort, Amsterdam, New York, Chicago, Tokyo et Singapour, vous pouvez observer la chaîne d'une région proche du leader actuel ou à venir dans chaque groupe.
Avec ce contexte physique et de programmation établi, nous pouvons parler des flux de données de Solana. Dans cet article nous nous concentrons sur trois que les développeurs rencontrent souvent:
- WebSocket (WS)
- Geyser gRPC
- ShredStream (UDP shreds)
Nous examinerons le calendrier des données que chacun voit, les caractéristiques de transport qu'ils possèdent et ce qu'ils sont réellement bons pour.
L'objectif n'est pas de choisir quelque chose parce que le nom sonne rapidement, mais de comprendre comment Solana fonctionne lui-même et comment les protocoles sous-jacents se comportent, puis de connecter cela aux performances de l'application et UX de manière concrète.
Différences de temps dans le flux des données de Solana
La première étape est de comprendre quand, dans le pipeline interne de Solana, différents types de données apparaissent réellement.
En gros, il y a trois étapes qui sont utiles pour le raisonnement sur la performance.
La première étape est Shreds.
Validateurs échange Shreds sur UDP afin de construire des blocs. Au cours de cet échange, ce qui circule sur le réseau est des données qui n'ont pas encore été entièrement assemblées en bloc. Si vous pouvez profiter de cette étape, vous voyez des changements sur la chaîne le plus tôt possible. Le compromis est que, parce que c'est UDP, vous devez assumer la perte de paquets et les arrivées hors-commande et concevoir votre système en conséquence.
La deuxième étape est Geyser gRPC.
Après qu'un validateur ait reçu Shreds et formé et confirmé un bloc, il peut exposer les résultats sous une forme structurée via des plugins Geyser. C'est là que Geyser gRPC flux proviennent: ils émettent des événements tels que des blocs, des journaux et des mises à jour de compte. Le timing est une étape plus tard que Shreds, mais les données sont déjà organisées, ce qui facilite la consommation des applications.
La troisième étape est HTTP RPC et WebSocket.
Une fois que les données ont passé par Geyser et d'autres traitements internes et ont été écrites dans les magasins internes de nœud, il devient disponible par JSON-RPC et WebSocket les notifications. Des méthodes comme getBalance, getProgramAccounts, et les abonnements log sont tous lus à partir de cet état stocké. Sur le plan du timing, il se trouve derrière les notifications de Geyser. API calque que la plupart des applications voient en premier.
Résumant ces trois étapes:
- Les shreds sont des données brutes très proches du moment de la propagation.
- Geyser gRPC fournit des données structurées au point où les blocs sont confirmés.
- RPC / WebSocket exposer les données stockées comme API vous demandez après le fait.
Quelle étape vous observez détermine à quel stade vous pouvez détecter les changements sur la chaîne. Cette différence de temps à elle seule crée déjà un écart de rendement important.
Caractéristiques du transport: gRPC, WebSocket, et TLS
Le timing est un axe. Le deuxième axe est la façon dont les données sont effectivement transportées.
Shreds utilise UDP.
UDP a de petits en-têtes et ne nécessite pas de configuration de connexion. Il ne fournit pas de garanties de retransmission ou de commande, mais en échange il minimise la latence. Pour quelque chose comme Shreds, où les données sont redondamment propagées entre de nombreux validateurs, cette simplicité et vitesse est exactement ce que vous voulez.
Geyser gRPC exécute TCP en utilisant un protocole binaire.
Streaming RPC, compression d'en-tête et encodage binaire lui permettent de déplacer les données plus efficacement que HTTP+JSON typique. Il est bien adapté pour la consommation continue d'événements structurés dans les moteurs, les systèmes de surveillance et les pipelines d'analyse.
WebSocket TCP plus TLS, avec des charges utiles JSON.
L'avantage clé est que les navigateurs et les piles web standard peuvent l'utiliser directement, c'est pourquoi il est partout dans dApps et les robots légers. L'inconvénient est que le texte JSON doit être analysé, et les en-têtes plus le chiffrement ajoutent des frais généraux. Parmi les trois, c'est le modèle le plus lourd.
En plus de cela, TLS lui-même ajoute une autre couche de coût.
Lorsque vous utilisez https, wss, ou gRPC-TLS, chaque connexion doit effectuer une poignée de main et chiffrer et déchiffrer les charges utiles. Pour les applications web générales, cela est généralement acceptable et même pas remarqué. Pour les stratégies où des dizaines de millisecondes comptent pour UX ou PnL, les frais généraux sont visibles.
Le point important est que:
- Le moment où vous voyez les données (Shreds / Geyser / RPC)
- La façon dont vous le transportez (UDP / gRPC / WebSocket / TLS)
sont des préoccupations distinctes, mais les deux ont une forte influence sur votre latence finale et UX.
Mise en contexte de la vitesse: timing et transport
Avec ces pièces en place, vous pouvez raisonner sur la vitesse plus concrètement.
Du point de vue du moment:
- Les shreds voient la première étape.
- Geyser gRPC vient ensuite.
- RPC / WebSocket venir en dernier.
Du point de vue des transports:
- UDP est le plus léger et le plus rapide.
- gRPC over TCP est le suivant, avec un streaming binaire efficace.
- WebSocket avec JSON et TLS est généralement le plus lourd.
Si vous normalisez pour la même région, le même matériel, le même chemin réseau, la commande de vitesse technique est:
- UDP (Shreds)
- gRPC (Geyser)
- WebSocket (JSON-RPC les notifications)
Bien sûr, c'est une vitesse isolée. Dans les systèmes réels, vous ne pouvez pas regarder seulement la latence. Vous devez également tenir compte de la fiabilité, des exigences d'exactitude, des coûts de développement et de la complexité de votre équipe.
Fiabilité et coût de développement: pourquoi WS > gRPC > UDP en pratique
Dans de nombreux projets réels, l'ordre dans lequel les flux de données sont adoptés est presque le contraire du classement de vitesse technique:
- Première WebSocket
- Alors Geyser gRPC
- Enfin Shreds / UDP
Ce n'est pas un accident.
Shreds (UDP) sont les plus rapides, mais vous devez concevoir pour les données manquantes et hors-commande dès le début.
Vous ne pouvez pas supposer que chaque paquet arrive et que toutes les données sont parfaitement alignées. Votre logique doit gérer les lacunes, se réconcilier avec d'autres flux si nécessaire, et tolérer le bruit. Le paiement est une latence minimale, mais la mise en oeuvre et les opérations deviennent significativement plus difficiles.
Geyser gRPC vous donne des données qui ont déjà été confirmées et structurées à l'intérieur du nœud.
Cela facilite la consommation. Les moteurs de recherche, les systèmes d'alerte, l'analyse en chaîne et les indexeurs peuvent tous construire sur Geyser avec un bon équilibre de vitesse, de fiabilité et d'effort de mise en œuvre. Pour de nombreuses équipes, c'est la deuxième étape naturelle une fois WebSocket- seulement les réglages atteignent leurs limites.
WebSocketL'avantage principal est qu'il se branche directement dans les navigateurs et l'infrastructure web normale.
dApp frontends et services légers peuvent l'utiliser avec les outils et bibliothèques existants, et des échantillons de code sont largement disponibles. Pour expédier une première version de votre produit, WebSocket est souvent le point de départ le plus pratique, surtout si vous avez déjà résolu le problème de distance à validateurs.
Donc en théorie, l'ordre de vitesse est UDP > gRPC > WS.
Dans la pratique, l'ordre d'adoption est généralement WS > gRPC > UDP.
Vous devez garder les deux axes à l'esprit et choisir en fonction de votre phase actuelle et de vos objectifs au lieu de poursuivre un label abstrait « fastest ».
Quelles humiliations Geyser gRPC travailler ensemble
Une fois que vous allez au-delà de l'accord de vitesse de base et commencer à prendre soin environ toutes les dizaines de millisecondes, la question clé devient comment combiner Shreds et Geyser gRPC.
Les shreds sont pour être les premiers à remarquer.
Si vous pouvez recevoir des Shreds près du leader actuel, vous pouvez détecter des changements sur la chaîne des dizaines à des centaines de millisecondes plus tôt que quelqu'un ne regardant que Geyser ou RPC. Pour les stratégies où cet écart se traduit directement en PnL, cela compte beaucoup. Le compromis est que vous acceptez le bruit et la conception pour lui.
Geyser gRPC est pour confirmer et raisonner correctement.
Au moment de la confirmation de bloc, Geyser émet des journaux, des changements de compte et d'autres événements structurés. Vous pouvez les brancher dans votre logique de stratégie, les contrôles des risques, les indexeurs et les systèmes de surveillance. Il est plus lent que Shreds, mais les données sont cohérentes et beaucoup plus faciles à raisonner.
Un modèle commun dans le domaine est:
- Utilisez Shreds pour détecter les occasions et assembler les transactions candidates le plus rapidement possible.
- Utilisation Geyser gRPC simultanément pour vérifier les blocs et les journaux et pour piloter votre logique principale et votre surveillance.
Cette séparation vous permet de pousser la latence tout en gardant votre prise de décision fondée sur des données stables et vérifiables.
TLS, terminaux partagés et nœuds dédiés
Jusqu'à présent, nous avons supposé que le nœud et le réseau sous-jacents étaient les mêmes. En réalité, il y a une autre différence structurelle énorme: que vous utilisiez un endpoint partagé ou un nœud dédié.
Un endpoint partagé est utilisé par de nombreux locataires à la fois.
Il est exposé sur Internet public, et le trafic traverse un périmètre de sécurité. Le chiffrement est obligatoire; vous ne pouvez pas simplement désactiver TLS. Le coût du cryptage, du décryptage et des poignées de main est parfaitement acceptable pour l'utilisation normale de dApp, mais apparaît si vous essayez de raser toutes les millisecondes possibles dans un contexte de style HFT.
Un nœud dédié est réservé à un seul locataire.
Parce que vous pouvez restreindre l'accès par adresse IP et isoler l'environnement, vous obtenez l'option pour désactiver TLS et utiliser un HTTP ou un texte clair gRPC. Vous ne partagez pas CPU, mémoire, disque I/O, ou bande passante réseau avec d'autres clients, de sorte que votre latence ne saute pas autour parce que quelqu'un d'autre exécute une lourde charge de travail sur la même machine.
Si vous dirigez vos Shreds, Geyser gRPC et RPC tous sur des nœuds dédiés, tous ces flux fonctionnent dans un environnement qui est isolé des autres locataires et de TLS au-dessus.
Cette combinaison fait que les configurations dédiées atteignent des plages de latence qui partagent des paramètres, par conception, ne peuvent pas atteindre même avec le même matériel.
Des nœuds partagés existent pour fournir des performances solides à de nombreux utilisateurs.
Des nœuds dédiés existent pour repousser les limites lorsque vous avez vraiment besoin du chemin le plus rapide possible.
Multi-régions et Shreds dédiés (transfert UDP)
Revenir à la distance et à la position de leader, tant que les leaders de Solana's tournent autour du globe, une configuration d'une seule région ne peut jamais être la plus rapide partout, tout le temps.
C'est là qu'interviennent les configurations de Shreds multi-régions.
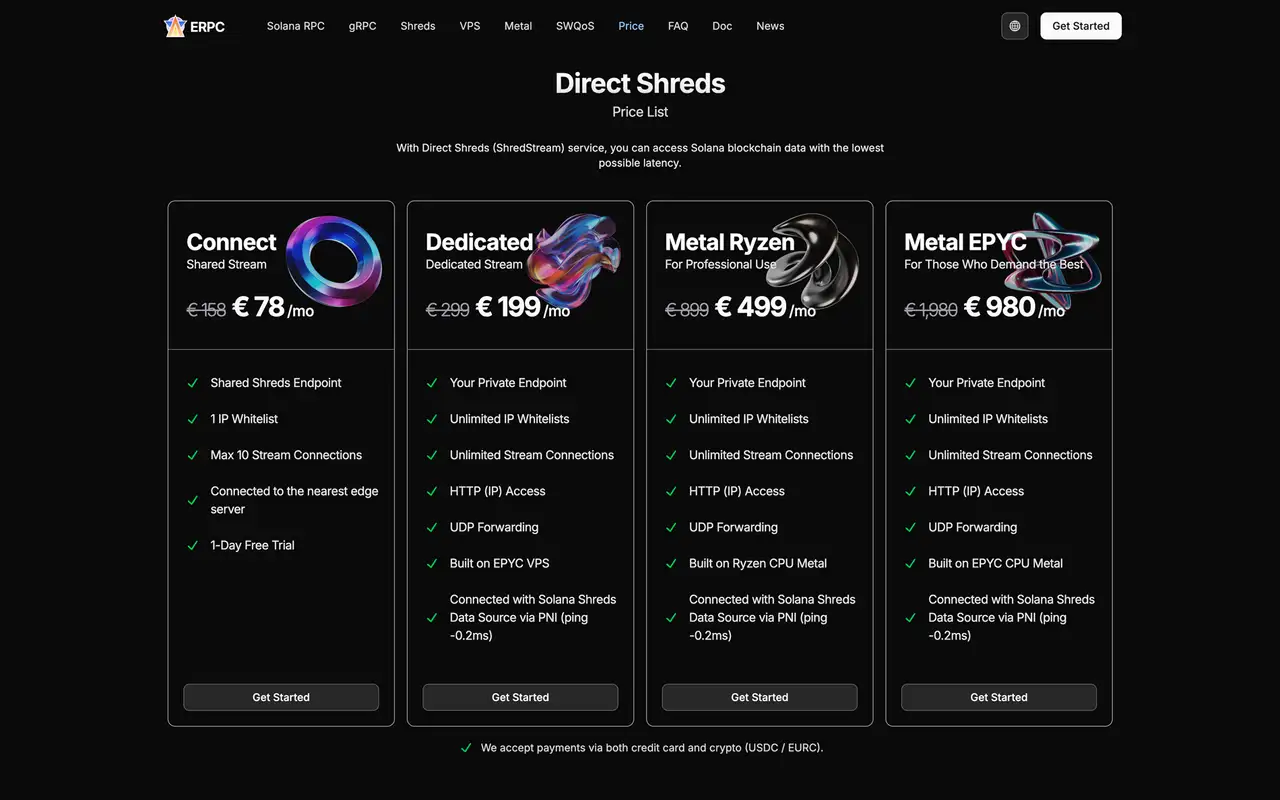
Les lustres dédiés (lustres prémium, lustres standard, lustres métalliques, éditions limitées et lignes similaires) combinent:
- Livraison UDP de Shreds le plus rapidement possible
- Serveurs dédiés avec jitter minimal
En déployant des Shreds dédiés dans plusieurs régions telles que Francfort, Amsterdam, New York, Chicago, Tokyo et Singapour, vous pouvez recevoir des Shreds proches du leader, quelle que soit la région actuellement favorisée.
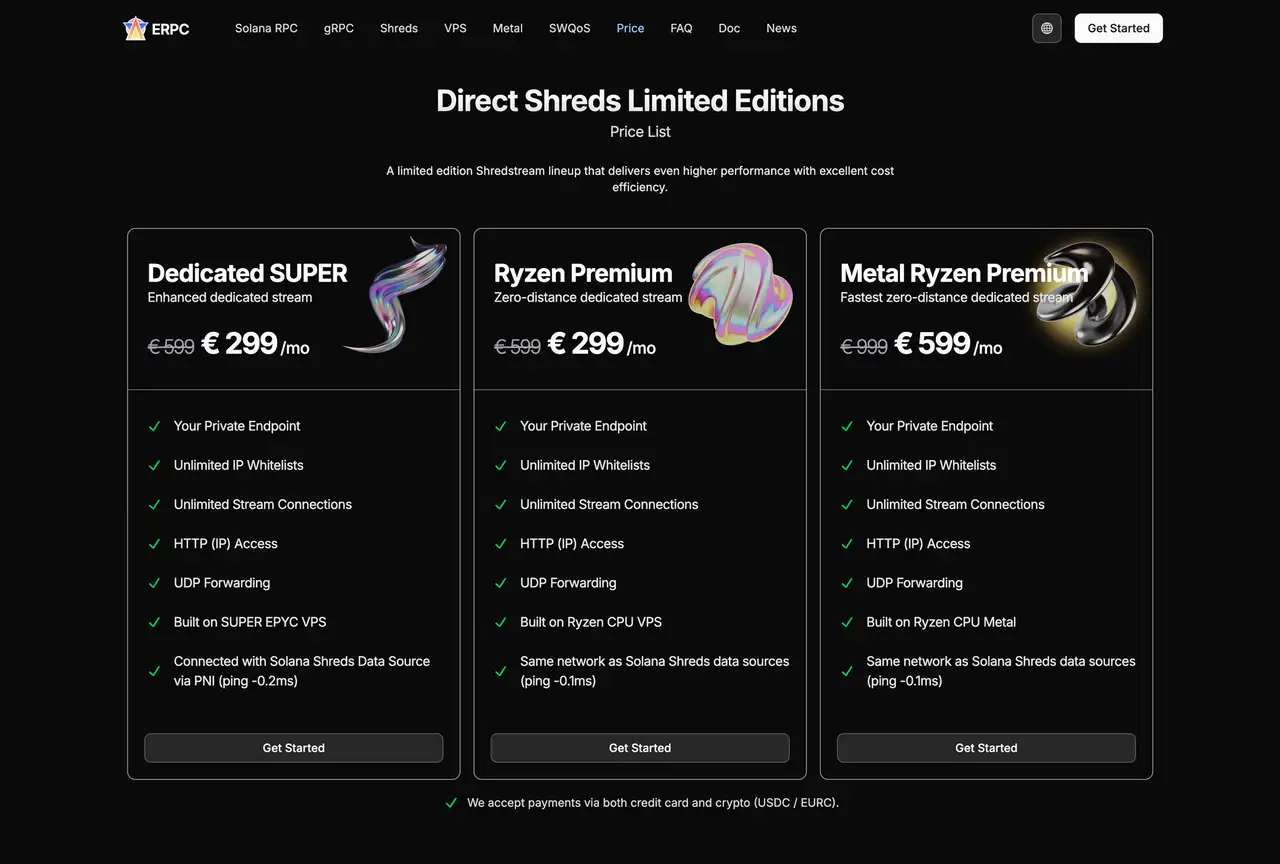
Un modèle commun est de s'abonner à plusieurs flux Shreds de différentes régions en même temps et d'agir uniquement sur celui qui arrive en premier.
Cela réduit l'impact de la latence long-courrier et de la congestion régionale et vous permet d'approximativement toujours près du leader de manière pratique.
Pour rendre les Shreds dédiés à plusieurs régions plus accessibles, ERPC fournit des coupons de réduction pour l'utilisation multi-régions:
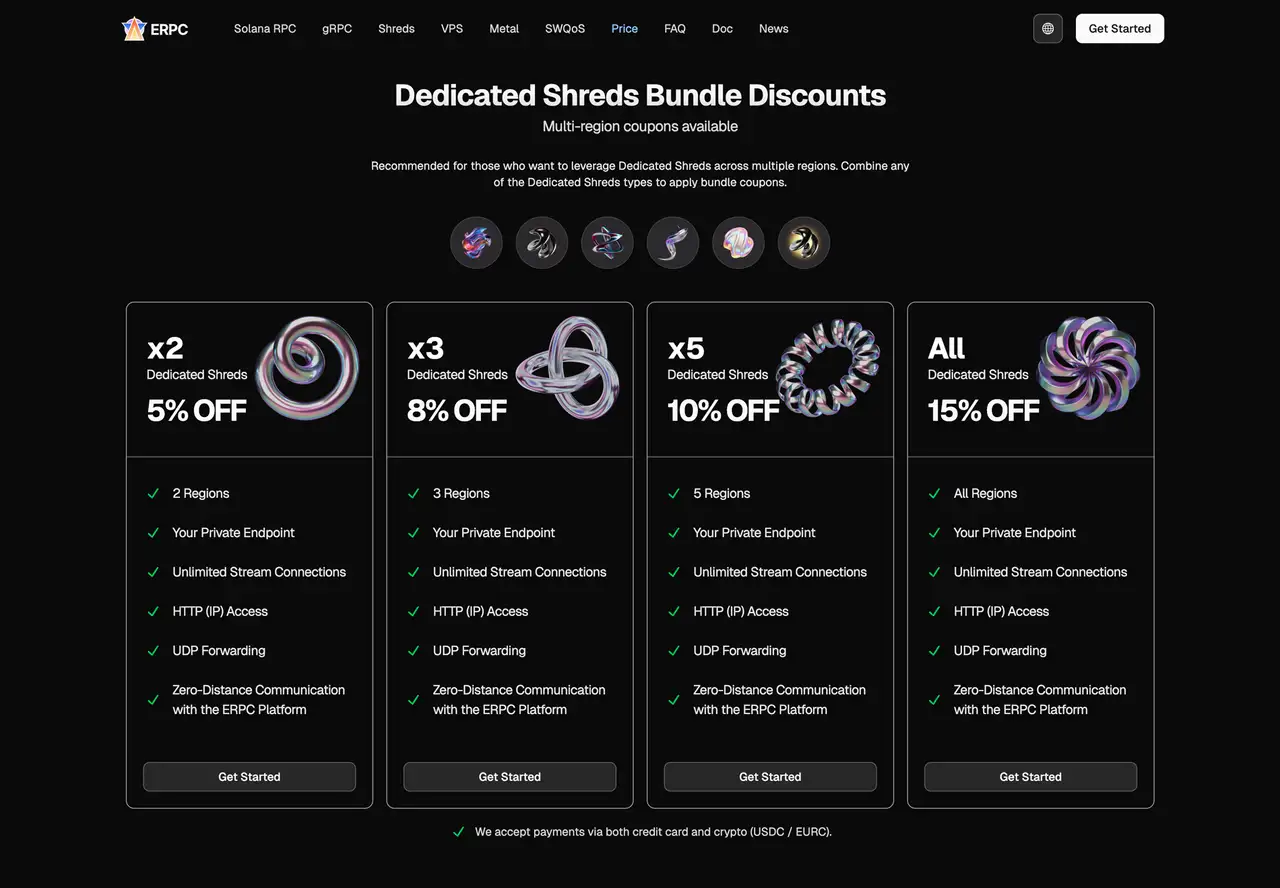
- 2 régions: 5% de réduction
- 3 régions: 8%
- 5 régions: 10% de réduction
- Toutes les régions: 15% de réduction
Cela facilite la conception de configurations où vous placez les niveaux Shreds les plus haut de gamme (par exemple Premium ou Metal) dans les régions les plus compétitives, et utilisez des options plus rentables pour prendre en charge les régions, tout en atteignant une large couverture.
Partage ShredStream Ensembles: une plus large on-ramp dans Shreds
Avant de vous engager à entièrement dédié Shreds partout, une multi-région partagée ShredStream la configuration peut être une étape intermédiaire très pratique.
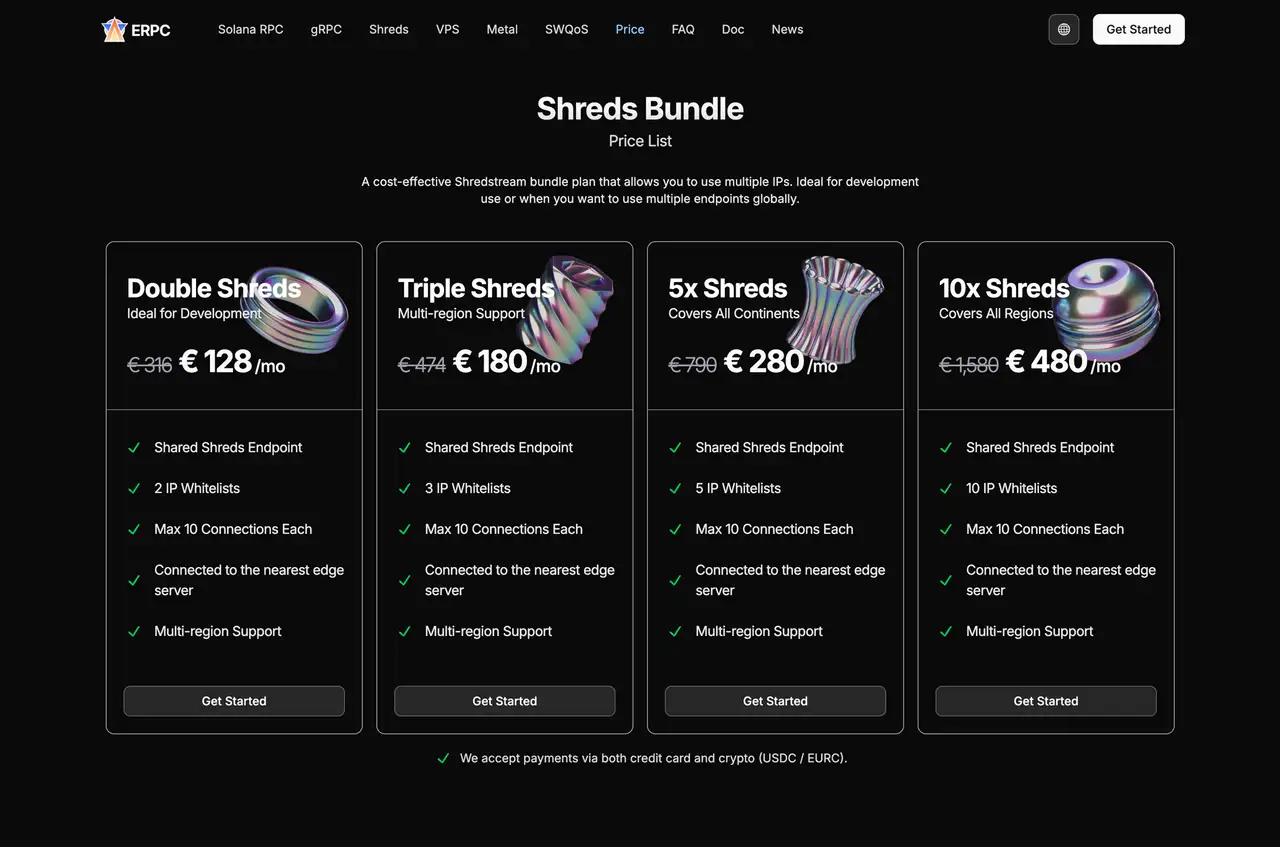
Partage ShredStream Ensembles vous permettent de consommer des Shreds partagés de plusieurs régions sous un seul plan.
En interne, ShredStream partagé prend les données du calque Shreds (UDP) et vous les livre via gRPC. La source est toujours Shreds, donc vous voyez l'information un pas plus tôt que Geyser gRPC, tout en bénéficiant de la commodité gRPC En streaming.
Pour ce qui est de l'alignement des couches:
- Les shreds dédiés via l'acheminement UDP sont les plus rapides, les plus proches de la propagation.
- Partage ShredStream est gRPC flux dérivé de Shreds, assis juste au-dessus de cela.
- Geyser gRPC vient après ça, au moment de la confirmation du bloc.
Partage ShredStream Les ensembles comprennent la liste blanche IP, 10 connexions et l'acheminement automatique vers le bord le plus proche. Cela permet de maintenir les coûts raisonnables tout en vous permettant d'utiliser simultanément les données provenant de Shreds dans des régions comme l'Asie, l'Amérique du Nord et l'Europe.
Au lieu de sauter directement dans les Shreds dédiés dans chaque région, vous pouvez:
- Commencez par un ShredStream partagé Ensemble pour obtenir une expérience pratique avec les données basées sur Shreds.
- Utilisez les journaux et les données de performance pour comprendre où il fait le plus de différence.
- Migrer des régions à fort impact vers des Shreds dédiés une fois que vous avez des preuves et une analyse de rentabilisation claire.
Étapes pratiques par phase de développement
Tout mettre en place, c'est plus facile de penser en termes de phases.
Dans la phase 1, choisissez la bonne région et la bonne distance, puis construisez votre dApp ou votre bot en utilisant RPC et WebSocket.
Obtenir la région et le placement du réseau correctement donne souvent de grandes améliorations UX même avant de toucher Shreds ou gRPC. Pour lancer un produit, WebSocket est un choix très rationnel, surtout de la façade.
Dans la phase 2, ajouter Geyser gRPC renforcer les moteurs, la surveillance et l'analyse.
Geyser gRPC vous permet de consommer efficacement les événements de bloc, de journal et de compte et de construire des indexeurs robustes, des systèmes d'alerte, et externe API sur eux. Il établit un bon équilibre entre la vitesse, la fiabilité et le coût de développement et est une étape naturelle de la seconde étape pour de nombreuses équipes.
Au cours de la phase 3, introduire Shreds et UDP, où les différences de latence affectent directement PnL ou UX.
En déployant des Shreds dédiés dans plusieurs régions et en utilisant des réductions multi-régions, vous pouvez entrer la bande de latence requise pour HFT, MEV, et les stratégies à 0-slot sans tout concevoir à partir de zéro en un seul coup.
Le point clé n'est pas UDP est théoriquement plus rapide, donc utiliser seulement UDP partout.
La clé est de regarder votre phase et votre économie, puis de décider où et quand investir dans Shreds et l'infrastructure dédiée déplace réellement l'aiguille.
Utilisation ERPC Groupes et VPS comme fondation
Les ERPC Les plans d'ensemble sont conçus pour vous donner une fondation complète:
- RPC (HTTP/ WebSocket)
- Geyser gRPC
- Partage ShredStream gRPC
Tous sous une seule structure.
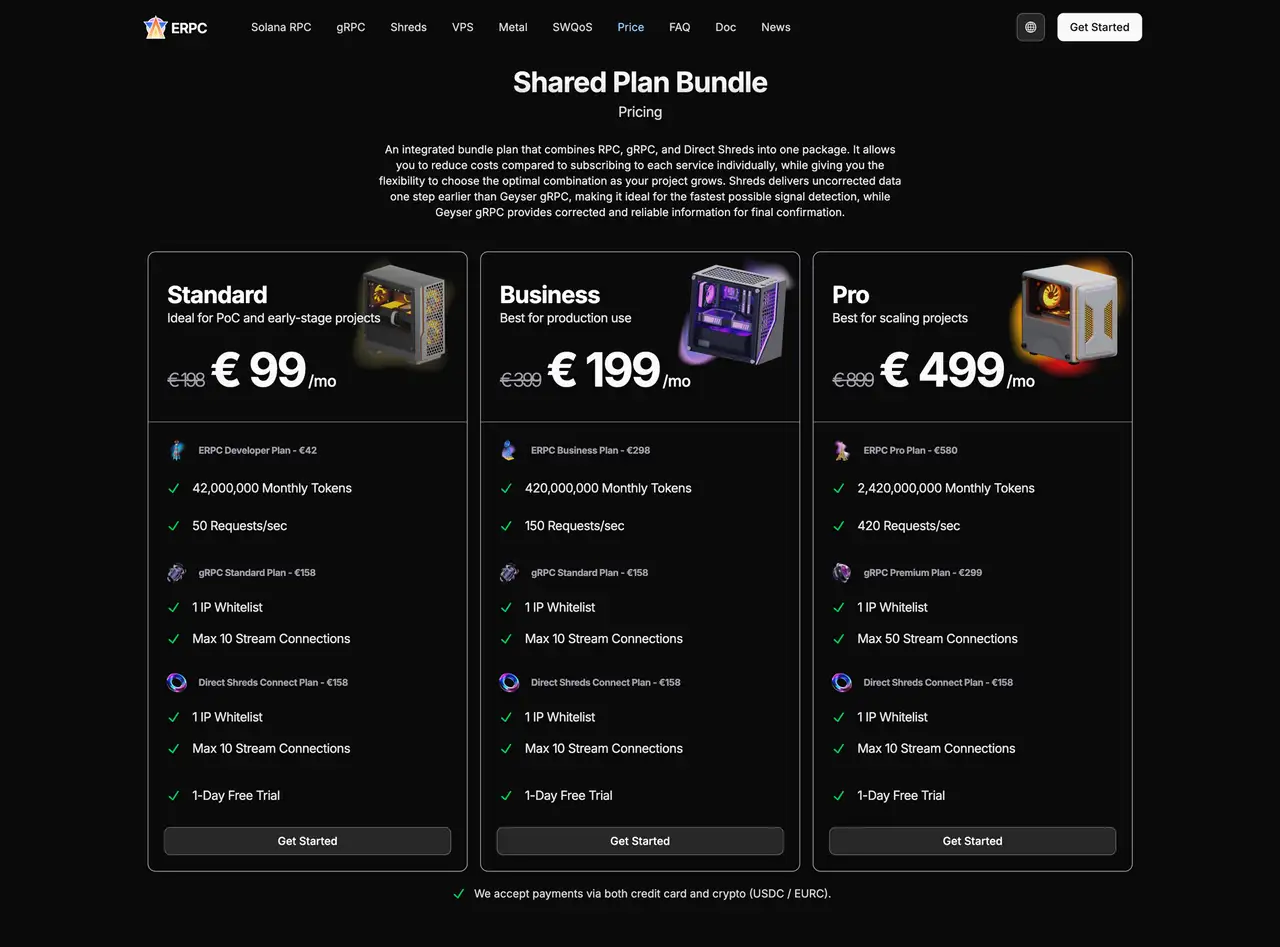
Vous pouvez continuer à utiliser RPC et WebSocket comme principale interface de production, tout en expérimentant Geyser gRPC et ShredStream sur le même réseau.
Parce que tout fonctionne sur une infrastructure unifiée, vous pouvez comparer le comportement et les performances directement et prendre des décisions basées sur des mesures réelles plutôt que sur des hypothèses.
En plus de cela, vous pouvez combiner ceci avec VPS lignes qui vivent à l'intérieur de la même ERPC réseau, comme EPYC VPS et Ryzen Premium VPS.
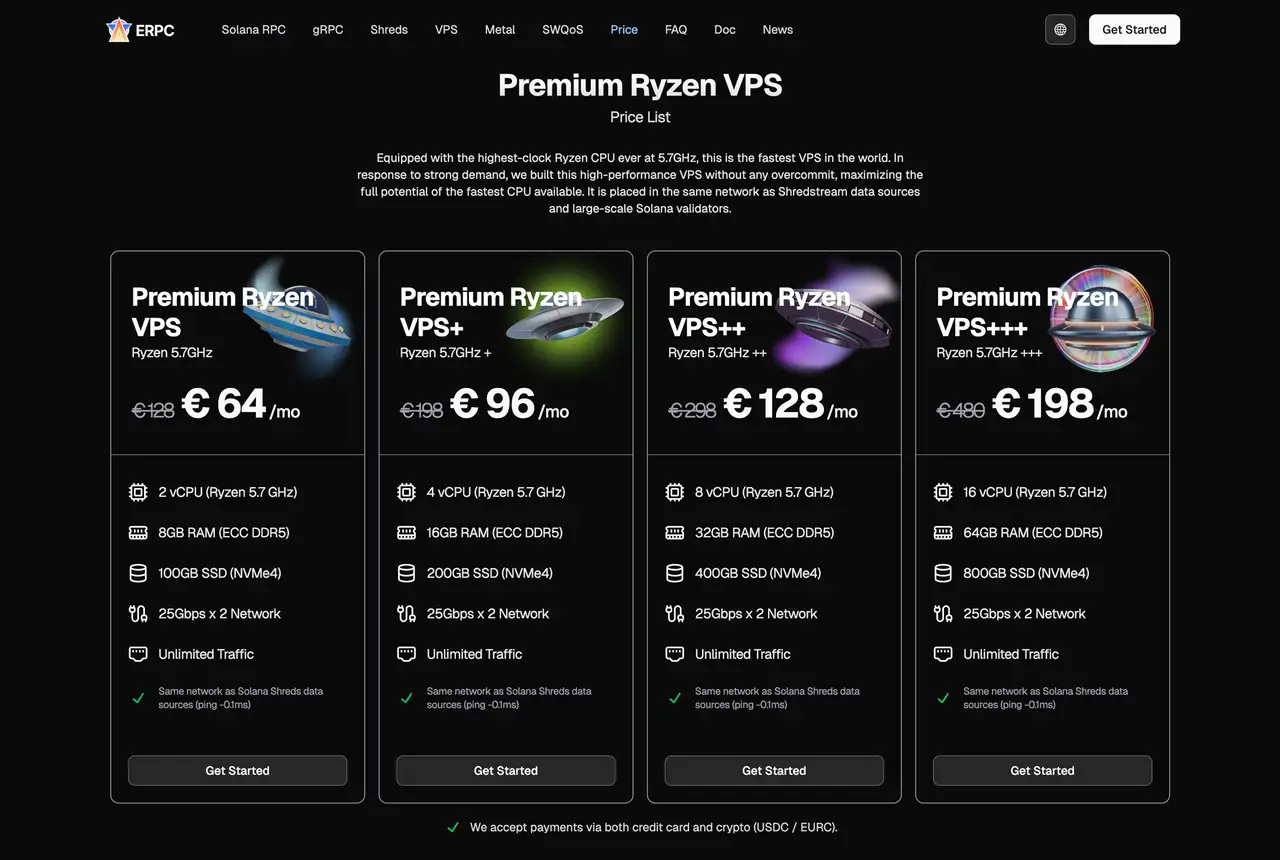
Cela vous permet d'écouter, en un seul endroit:
- Distance jusqu'aux validateurs Solana
- Choix des flux de données (WS, gRPC, Shreds)
- Performance du matériel
Une approche pratique consiste d'abord à garantir les régions appropriées et ERPC Ensemble + VPS Fondation, puis allumez des couches plus rapides (Geyser, Shared Shreds, dédié Shreds) au fur et à mesure que vos besoins et votre économie évoluent.
Conclusion: conception des performances de Solana à partir du moment, du transport et de la distance
La performance et l'UX d'une application Solana proviennent d'une combinaison de facteurs:
- Où se trouvent vos serveurs
- Comme vous êtes proche du leader de chaque groupe
- À quel moment vous recevez les données en chaîne
- Quel transport et quel protocole utiliser
- Comment votre logique d'application réagit en plus de cela
La distance et la position de tête forment la base. En plus de cela, vous avez:
- Déchiquetés pour la première étape
- Geyser gRPC pour les données confirmées et structurées
- RPC / WebSocket pour accéder à l'état stocké via API
Et du côté du transport, vous avez:
- UDP
- gRPC sur TCP
- WebSocket sur TCP avec JSON et TLS
Choisir un flux ou un protocole par nom ou par marketing seul ne suffit pas.
Le point est de sélectionner une structure qui correspond à votre cas d'utilisation sur ces trois axes: le moment, les caractéristiques de transport et la distance aux validateurs pertinents.
ERPC et Validators DAO fournissent un réseau axé sur Solana, RPC / gRPC / les services ShredStream, VPS lignes, et rabais multi-régions pour Shreds dédiés, de sorte que vous pouvez construire ces structures à un coût réaliste et les évoluer à mesure que vos besoins augmentent.
Si vous souhaitez discuter de la conception de flux de données, l'optimisation de distance réseau, ou des combinaisons de Shreds dédiés, Shared ShredStream Groupes, groupes, et VPS, n'hésitez pas à contacter Validators DAO Discord.
- ERPC: https://erpc.global/en
- SLV: https://slv.dev/en
- elSOL: https://elsol.app/en
- Epics DAO: https://epics.dev/en
- Validators DAO Discord: https://discord.gg/C7ZQSrCkYR
Actualités


